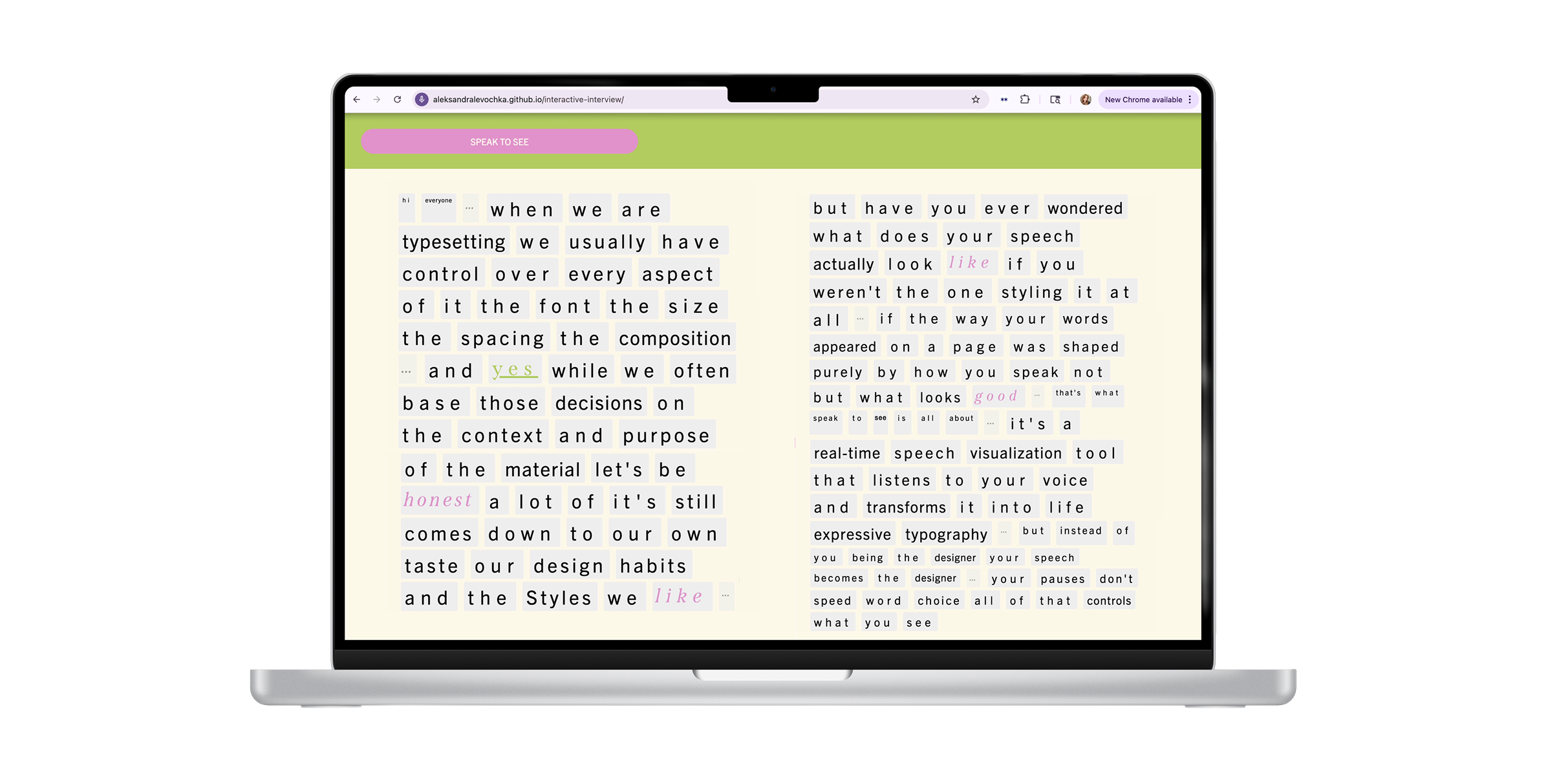
An experimental voice-to-text tool that stylizes spoken words based on how they are said, turning speech into a visual echo of your voice.
Tools: JavaScript, HTML, CSS, AFFIN Json, Web Speech Recognition
Interactive Web Tool
SPEAK TO SEE

WHAT IS SPEAK TO SEE?
When typesetting, we usually control every stylistic decision. But what if our speech styled itself, based on
the data of how we speak, not our taste?

WHAT IF WE LET SPEECH DECIDE?
The whole project is rooted in this very question. Instead of
a designer styling text based on their preferences, the tool turns spoken words into styled
text based on how they’re said. The time between words, the sentiment they carry, and even the
length
of pauses.
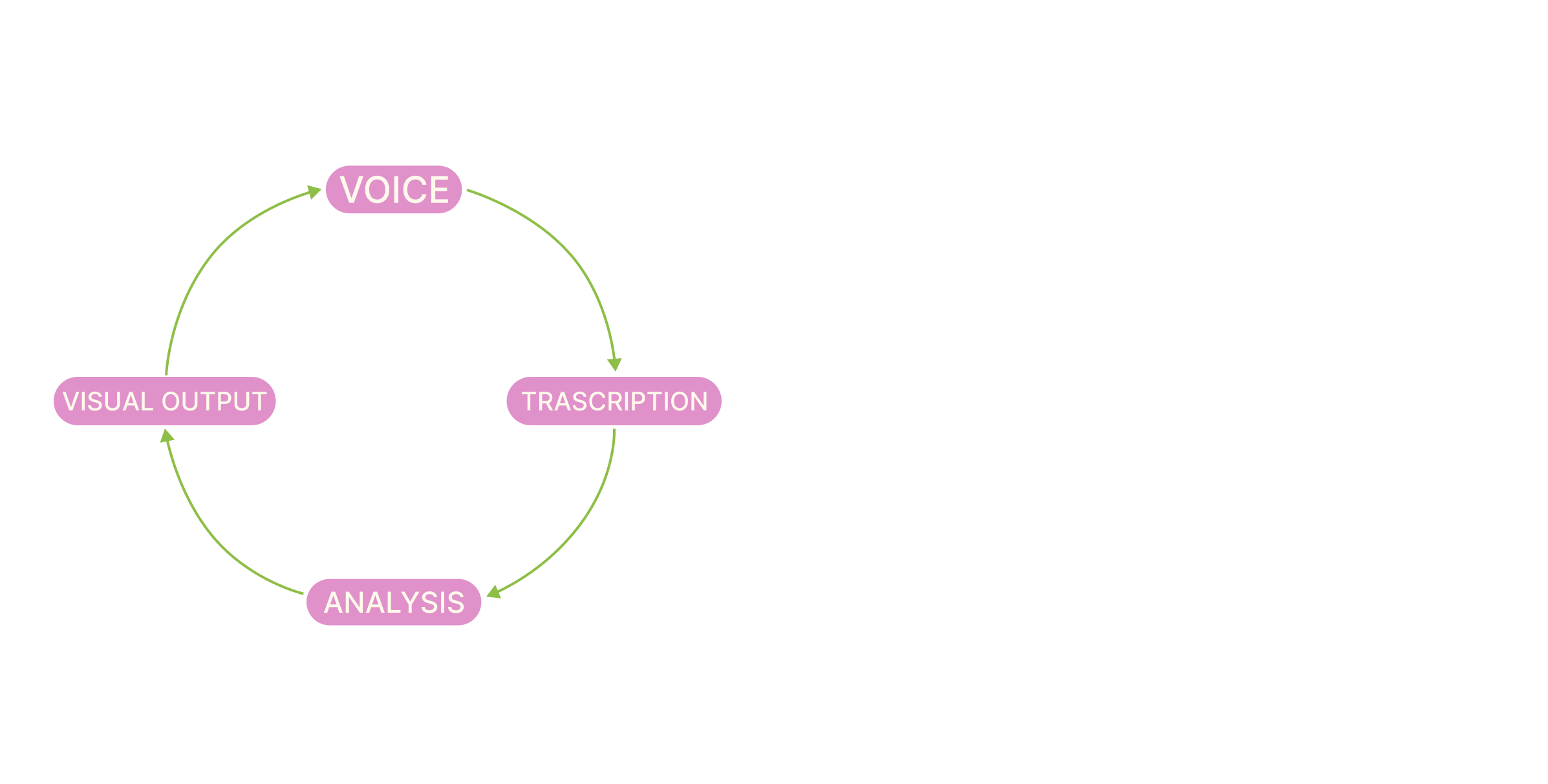
MATH + LOGIC BEHIND
The tool stores timestamp data, performs real-time calculations on pause length and sentiment, and applies styling based on those variables.
→ Timestamps are stored for chunks of heard speech
→ Pause durations are calculated in milliseconds
→ Sentiment scores are pulled from a JSON dictionary
→ Font size and letter spacing are generated through conditional formulas
→ Fading is handled by a gradual opacity function that simulates memory loss